
Redis의 개념
Redis의 정의
레디스는 고성능 키-값 저장소로서 문자열, 리스트, 해시, 셋, 정렬 셋 형식의 데이터를 지원하는 NoSQL이다.
스케일 업 vs 스케일 아웃
스케일 업(Scale Up) : 단일 서버(하드웨어)의 성능을 증가시켜서 더 많은 요청을 처리하는 방법이다.
스케일 아웃(Scale Out) : 동일한 사양의 새로운 서버(하드웨어)를 추가하는 방법이다.
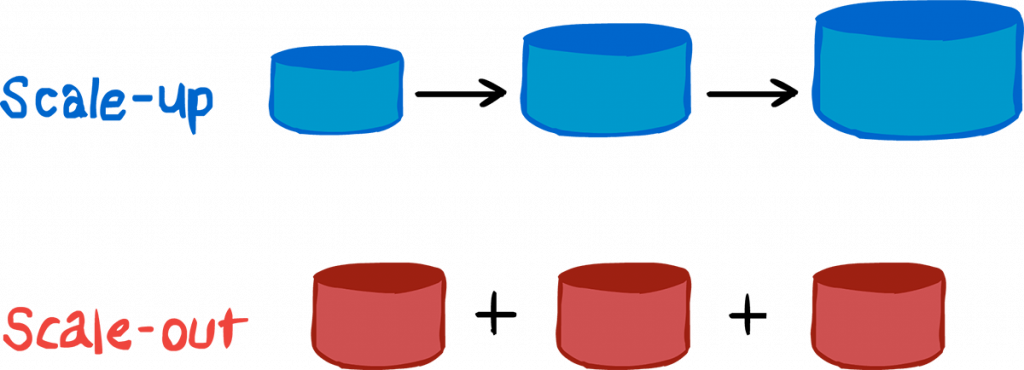
스케일 업은 단일 하드웨어의 성능을 높이기 위하여 CPU, 메모리, 하드디스크를 업그레이드하거나 추가하는 것을 말한다.(상황에 따라 서버자체를 교체하기도 한다.)
스케일 업의 명확한 한계는 하나의 장비에 설치 할 수 있는 CPU 및 메모리와 디스크의 수에 제한이 있다.
또한, 소프트웨어 구조상 아무리 스케일 업을 한다고해도 하드웨어의 퍼포먼스의 물리적 한계가 존재한다.
※ MySQL 성능 증가를 위한 스케일 업
MySQL 테스트 자료에 따르면 CPU 코어를 4개부터 증가시켜서 성능 테스트를 한 결과 16코어를 넘어간 순간부터는 성능 증가가 미미하다.
MySQL Connection 또한 16개(MySQL 5.6버전부터 32개)가 넘어가는 순간부터 성능 증가가 미미하다.
NoSQL은 처음부터 스케일 아웃을 염두에 두고 설계되었기 때문에 데이터 증거나 요청량이 증가하더라도 동일하거나 비슷한 사양의 새로운 하드웨어를 추가하면 대응이 가능하다.
데이터가 적거나 또는 요청량이 적을 때는 RDBMS를 사용하더라도 서비스를 제공하는 데 문제가 없다.
하지만 데이터 증가량을 측정하기 불가능하거나 서비스 요청량의 증가를 예측하기 어려운 상황에서는 NoSQL을 저장소로 사용하는 것이 현명한 성택일 것이다.
Redis의 특징
- 영속성을 지원하는 인메모리 데이터 저장소
- 읽기 성능 증대를 위한 서버 측 복제를 지원
- 쓰기 성능 증대를 위한 클리이언트 측 샤딩(Sharding)을 지원
- ANSI C로 작성되어 있기 때문에 ANSI C 컴파일러가 작동하는 어느 곳이든 실행이 가능
- 레디스 클라이언트는 대부분의 언어로 포팅되어 있다.(참조:http://redis.io/clients)
- 문자열, 리스트, 해시 , 셋, 정렬된 셋과 같은 다양한 데이터형을 지원
※ 레디스와 멤캐시드의 차이
- 멤캐시드 : 본질적으로 고성능 분산 메모리 객체 시스템이지만, 원래는 동적 웹 서비스의 DB 부하를 경감시키는 것이 목적이었다.
- 레디스 : 오픈소스이며 향상된 Key-Value 저장소다. 값으로 문자열, 리스트, 해시 , 셋, 정렬된 셋을 포함할 수 있기 때문에 종종 데이터 구조 서버로 지칭됨.
NoSQL의 정의
마틴 파울러 <NoSQL : 빅데이터 세상으로 떠나는 간결한 안내서(인사이트, 2013)>에는 NoSQL이 아래의 조건을 만족하는 데이터 저장소라고 기술되어 있다.
- 대용량 웹 서비스를 위하여 만들어진 데이터 저장소
- 관계형 데이터 모델을 지양하며 대량의 분산된 데이터를 저장하고 조회하는 데 특화된 저장소
- 스키마 없이 사용 가능하거나 느슨한 스키마를 제공하는 저장소
CAP 정리
CAP란? 2000년에 전산학자 에릭 브루어가 이 명제를 가설로서 제시하였다.
이후 2002년 세스 길버트와 낸시 린치가 이를 증명하였다. (브루어의 정리라고도 불림)
CAP는 ‘일관성(Consistency), 가용성(Availability), 분할 허용성(Partition Tolerance) 모두를 동시에 지원하는 분산 컴퓨터 시스템은 없다’라고 정의되어 있다.
- 일관성(Consistency): 모든 노드가 같은 순간에 같은 데이터를 볼 수 있다.
- 가용성(Availability): 모든 요청이 성공 또는 실패 결과를 반환할 수 있다.
- 분할 허용성(Partition Tolerance): 메시지 전달이 실패하거나 시스템 일부가 망겨져도 시스템이 계속 동작할 수 있다.
정리를 해보면 예를들어 기업용 어플리케이션 개발자면 웹 서버와 DB 서버를 동일한 시스템에 설치하지는 않을 것이다.
일반적으로 웹 서버와 DB 서버는 각각 다른 하드웨어 설치한다. 이와 같은 단일 시스템이 아닌 ‘다중 시스템 환경에서 소프트웨어가 작동하는 것’을 분산 컴퓨팅이라 한다.
대부분의 NoSQL은 기본적으로 분산 환경에서 잘 동작하도록 설계되어 있다. 즉, 동일한 성격의 데이터가 물리적으로 다른 하드웨어에 저장되고 조회된다.
이때 각 NoSQl은 일관성, 가용성, 분할 허용성 가운데 두 가지 속성만을 지원하며 나머지 한 속성은 특정 조건에서만 만족한다.
CAP 정리에서 기초한 세 가지 속성 중에서 어떠한 두 속성을 지원하는지에 따라서 NoSQL의 특징이 달라진다.
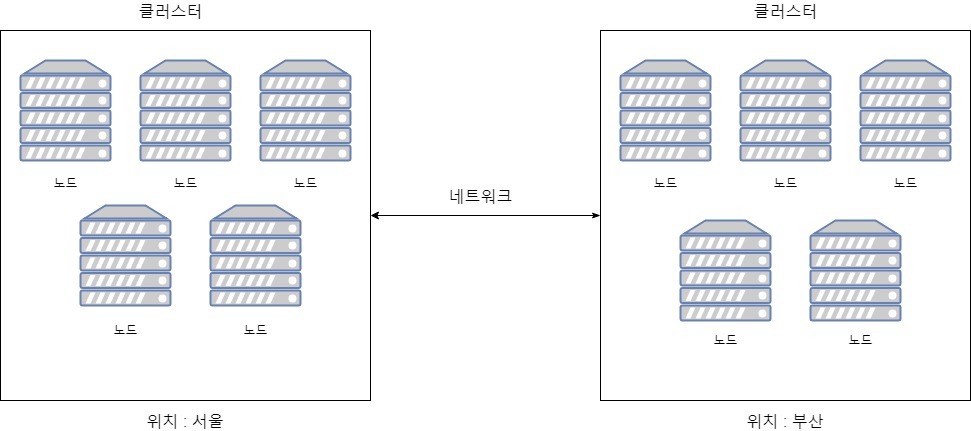
위 그림은 분산 시스템을 구성하는 개별 요소들을 나타내고 있다.
분산 시스템을 구성하는 각각의 하드웨어 또는 소프트웨어를 노드라고 부르며, 동일한 기능을 수행하는 노드들의 모음을 클러스터라고 한다. 분산시스템은 하나 혹은 그 이상의 다중 클러스터로 구성될 수 있다. 다중의 클러스터에서 각 클러스터는 동일 지역 혹은 지역적으로 떨어진 위치에 존재할 수 있다.
이때 각 클러스터간의 연결은 네트워크를 기반으로 한다.
참고
- 이것이 레디스다(한빛출판네트워크/정경석)